
Sparse attention mechanisms and several analogies with programming codes

Photo by Shubham Dhage
For this post we refer to the paper “Dynamic Inference with Neural Interpreters” by Rahaman et al. (2021).
Overview
A neural interpreter is a collection of modules almost resembling a programming code: it is a bunch of scripts which are made up of functions which are made up of lines of code. Essentially, this is an attention-based network and inputs to the model are routed through a sequence of functions in a way that is end-to-end learned.
Convolutional networks reuse computational units, like filters, laterally (once depth is fixed), meanwhile recurrent neural networks only reuse computational units (RNN cells) vertically, i.e., in depth. Such rigidity in the way networks reuse their units is believed to be one of the reasons for the poor generalization. Neural interpreter model aims to be an architecture made of independent and composable pieces, capable of relaxing this rigidity in computation reuse.
Input and Output
Assume that the input set contains vector embeddings of image patches or entire images. These elements are vectors of a certain dimension din. The input set additionally includes one or more learned vectors, called CLS tokens, for which the corresponding outputs interface with their respective classifiers. The output is another set of vectors whose dimension is dout (with the same cardinality as the input set).

Scripts
A neural interpreter is a stack of nₛ scripts mapping one set of vectors X = {x₁ , x₂, …} to another Y = {y₁ , y₂, …} with the same number of elements:
](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BY%7D+%3D+%5Cmathsf%7BNeural+%5C%3B+Interpreter%7D%28%5Cmathbf%7BX%7D%29+%3D+%5Cleft%5B+%5Cmathsf%7BScript%7D_%7Bn_s%7D+%5C%2C+%5Ccirc+%5C%2C+%5Ccdots+%5C%2C+%5Ccirc%5C%2C+%5Cmathsf%7BScript%7D_1+%5Cright%5D%28%5Cmathbf%7BX%7D%29++&bg=ffffff&fg=000000&s=1&c=20201002)

Increasing the number of scripts nₛ will increase the depth of the architecture. A script has four components:
- a type inference module;
- a type matching mechanism;
- a set of functions;
- an interpreter.
We will soon describe these four components.
Functions
Each script contains functions. Functions are vector-valued instructions to other components in the script. Formally, a function fᵤ is a pair (sᵤ, cᵤ) where sᵤ is called signature and cᵤ is called code (u is used as index). The signature is a normalized vector of dimensions dtype and indicates to the type matching mechanism (see below) what inputs are to be routed to fᵤ (note the analogy with coding). The vector cᵤ, a learned parameter for each function, is the code that tells the function what to do (further details in a moment). Each f has its own code that would always be the same.
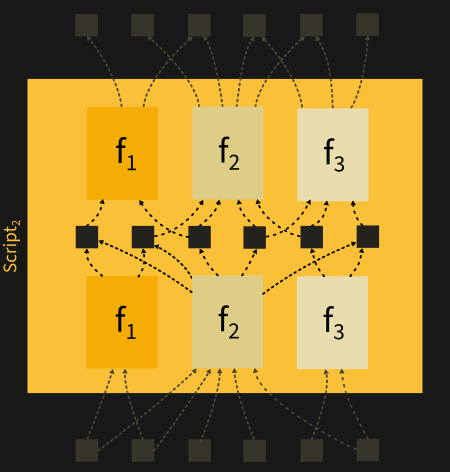
For example, f₁, f₂ and f₃ all share their global parameters but they all have their own codes. Samples can jump flexibly from one function to another. The way each sample is routed through the network is completely independent and it is determined on a per-sample basis. Every example has its own independent path to the network and the routing itself is completely learned.
Not all the examples are routed, so let’s see how an example gets to the functions’ scope.
Type Matching and Inference
Before getting to the functions, a sort of higher-level attention is performed on the set elements. Type matching is responsible for routing the information elements through functions. This is a three step procedure.
a) At the beginning, an input set element xᵢ is processed through an MLP module (called type inference module) to obtain a type vector tᵢ whose dimension is dtype. This vector lies in the same unit hypersphere 𝓣 containing the signature vectors sᵢ.
b) Consider a function fᵤ. Define a distance function based on the cosine similarity between tᵢ and signature sᵤ, that is d𝓣= 1 – sᵤ · tᵢ .
c) Successively, a sort of softmax with normalization is performed, returning a coefficient Cᵤᵢ. However, Cᵤᵢ is set to 0 if the distance between sᵢ and tᵢ is larger than τ, a value called truncation parameter. This introduces sparsity in the model. Fix u and i, then Cᵤᵢ is the compatibility between function fᵤ and set element xᵢ: xᵢ can be processed by fᵤ only if Cᵤᵢ is sufficiently large. If Cᵤᵢ = 0, then fᵤ cannot access xᵢ.

Modulated Linear layers and modulated MLPs
The following constructs are needed to define an attention mechanism later on. These constructs should be interpreted as programmable modules (the program is determined by the code c). Modulated linear layers act like linear layers with the only difference being that, instead of x, the linear transformation is applied to
x´ = x ⊗ LayerNorm(W𝒸 c)
where W𝒸 is a learnable matrix that constitutes a set of parameters shared among all functions in the same script (the symbol ⊗ denotes entry-wise product). In short

where W is a weight matrix and b is a bias term. Having defined modulated linear layer, one may also stack L of them (sharing the same code c) interspersed with GELU activation functions to get the modulated MLP:

ModAttn
A type of conditional (that is, conditioned by the code vector cᵤ of function fᵤ) multi-head attention mechanism is used. Queries, keys and values are evaluated using ModLin layers (instead of simple linear layers) for each head h:

Then, consider again the compatibility coefficients {Cᵤᵢ}; these quantities would serve as modulators when evaluating self-attention weights. Self-attention weights are given by the normalizing expression

where epsilon avoids divisions by ~0 terms and
![\displaystyle \tilde{W}_{uhij} = C_{ui}C_{uj}\left[ \mathsf{softmax}_j \left(\frac{ \mathbf{q}_{uhi} \cdot \mathbf{k}_{uhj} }{\sqrt{d_\textsf{key}}}\right) \right] \,.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctilde%7BW%7D_%7Buhij%7D+%3D+C_%7Bui%7DC_%7Buj%7D%5Cleft%5B+%5Cmathsf%7Bsoftmax%7D_j+%5Cleft%28%5Cfrac%7B+%5Cmathbf%7Bq%7D_%7Buhi%7D+%5Ccdot+%5Cmathbf%7Bk%7D_%7Buhj%7D+%7D%7B%5Csqrt%7Bd_%5Ctextsf%7Bkey%7D%7D%7D%5Cright%29+%5Cright%5D+%5C%2C.+&bg=ffffff&fg=000000&s=1&c=20201002)
For example, fix fᵤ and the head h. Then we have
![\displaystyle \tilde{W}_{ij} = C_{i}C_{j}\left[ \mathsf{softmax}_j \left(\frac{ \mathbf{q}_{i} \cdot \mathbf{k}_{j} }{\sqrt{d_\textsf{key}}}\right) \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctilde%7BW%7D_%7Bij%7D+%3D+C_%7Bi%7DC_%7Bj%7D%5Cleft%5B+%5Cmathsf%7Bsoftmax%7D_j+%5Cleft%28%5Cfrac%7B+%5Cmathbf%7Bq%7D_%7Bi%7D+%5Ccdot+%5Cmathbf%7Bk%7D_%7Bj%7D+%7D%7B%5Csqrt%7Bd_%5Ctextsf%7Bkey%7D%7D%7D%5Cright%29+%5Cright%5D+&bg=ffffff&fg=000000&s=1&c=20201002)
and, after normalization, the weight Wij is the attention weight between elements xᵢ and xⱼ. Intuitively, information about xᵢ and xⱼ is mixed by fᵤ at head h only if Wuhij is not 0. This can happen in two cases: 1) the compatibility factors are both non-zero (that is, fᵤ can access both xᵢ and xⱼ) or 2) self-attention weights (the softmax part) is close to zero. Finally, the following linear combination is computed

and the final output is

where the semicolon separating h from ui indicates that the results of various heads are folded (as usual in multi-head attention) into one single object.
Line of Code
A line of code layer is a ModAttn layer followed by a ModMLP layer (see figure below, on the right). Both these layers share the same condition vector and there are weighted residual connections between them.

A line of code (LOC) is a line of code layer applied in parallel streams, one per function, as shown in Fig. 5 (right). Inputs of a LOC, say {xᵤᵢ}, are written with an extra index u, meaning that this is a specific input to the function fᵤ. If a function fᵤ cannot access xᵤᵢ, then fᵤ acts on xᵤᵢ as the identity function. For example, focus on a particular function fᵤ and on its specific inputs {xᵤᵢ} as i vary. Then

where ãᵤᵢ is the output of the attention layer (ModAttn); then

where 
Interpreter
The interpreter layer is a stack of LOCs sharing the same function codes. The interpreter broadcasts a given set element to multiple parallel computational streams, one for each function. Let the number of stacked LOCs be nₗ. Let X = {x₁ , x₂, …} and Cᵤ = {Cᵤ₁, Cᵤ₂, …}, then

where

Essentially, the output is a weighted sum with compatibilies of the elements with the respective function as coefficients. Given a set of inputs and an instruction (the function code), the role of the interpreter is to execute that instruction and compute the output.
Increasing the number of LOCs nl increases the architecture depth and also the number of parameters.
Functions Iteration
We have already seen that the overall model is a stack of multiple scripts. A script can be expressed as a recurrent application of Function Iteration (FnIter)

where FnIter is defined as the composition of the type matching mechanism and the interpreter.
The number of function iterations nᵢ can increase without increasing the number of parameters, so FnIter can enable units sharing in depth.
Experiments
Some experiments have been conducted on subjects such as learning fuzzy boolean expressions, multi-task image classification abstract reasoning. However, we do not delve any further into such matters as it will only be time to determine whether this recent architecture is profitable or not.
Useful links
Original article on Neural Interpreters.
Nice discussion with authors (video).
