Short code analysis for a huge model

This is a brief code review about the Open Release of Grok-1 (link), whose code is found here. We’ll start at the entry point (the main function of run.py file) and only go through the essential steps – delving into the details would take too much time and effort for a short post.
Intro to Grok-1
Grok is a generative artificial intelligence chatbot developed by xAI, based on a large language model (LLM). The engine powering Grok is Grok-1, a 314 billion parameter Mixture-of-Experts model trained from scratch by xAI, which became open source under the Apache-2.0 license on March 17, 2024, when xAI released the base model weights and network architecture.
The repository readme cites: “This repository contains JAX example code for loading and running the Grok-1 open-weights model. Make sure to download the checkpoint and place the ckpt-0 directory in checkpoints…”. So we know that it is relatively easy to place the weights, the difficult part is that the weights file, the result of a very expensive training, is about 318GB! In fact, the same page warns that due to the large size of the model, a machine with enough GPU memory is required to test the model with the example code… good, however we are only interested in the code for now!
Some model details: a) base model trained on a large amount of text data, not fine-tuned for any particular task; b) 314B parameter Mixture-of-Experts model with 25% of the weights active on a given token; c) trained from scratch by xAI using a custom training stack on top of JAX and Rust in October 2023.
- Parameters: 314B
- Architecture: Mixture of 8 Experts (MoE)
- Experts Utilization: 2 experts used per token
- Layers: 64
- Attention Heads: 48 for queries, 8 for keys/values
- Embedding Size: 6,144
- Tokenization: SentencePiece tokenizer with 131,072 tokens
- Additional Features:
- Rotary embeddings (RoPE)
- Supports activation sharding and 8-bit quantization
- Maximum Sequence Length (context): 8,192 tokens
Grok’s performance is not superior to other particular models. On the Grok blog, they justify this as “It is only surpassed by models that were trained with a significantly larger amount of training data and compute resources like GPT-4. This showcases the rapid progress we are making at xAI in training LLMs with exceptional efficiency”. I would never have thought of producing an article on a model with a gargantuan number of parameters and unconvincing results but, at least, the code seems very understandable.
Code
The repository contains code that only needs 4 libraries other than Python: JAX, Haiku, Sentencepiece and NumPy. The script run.py simply 1) loads the checkpoint (weights file) and 2) samples from the model on a test input, i. e. after inserting some input text, the model returns a response. Clearly, we are only talking about inference, the training efforts are all wrapped up in the cumbersome checkpoint (weights) file.
Main function
The script run.py contains the main function, that is our entrypoint. A language model configuration (grok_1_model) is initialized using specific parameters. Inside, a Transformer model is defined with its parameters, together with MoE and sharding parameters (sharding is a technique used in distributed computing to partition data across multiple devices or processors, allowing for parallel processing). Then, an inference runner (“runner” refers to an instance of a class or object responsible for executing the language model for inference; it encapsulates functionalities such as loading the model, tokenizing input text, performing inference, and generating output) is set up using this model configuration. The InferenceRunner is initialized with certain parameters such as pad sizes, the actual runner (an object of the ModelRunner class located in the runners.py file), name, load, tokenizer path, local mesh configuration (this is the configuration of ) and between hosts configuration. Finally, the runner is initialized and executed (these two steps are dotted in the following picture and will be explored in the next sections) to generate text based on a given input prompt (inp).

Above, the main function essential view. There are two reduced parts (highlighted in grey) for Grok-1 model config and inference runner config; these parts are expanded below.


Inference Runner initialization
After setting all the necessary parameters, the initialize() function from the inference runner object, is executed. This triggers a cascading initialization sequence, involving multiple regions of code, which is difficult to fully describe in a few lines – we’ll try!
inference_runner.initialize() calls initialize function (1) from InferenceRunner class. In turn, this last initialization function calls another initialize function (2) from ModelRunner class.
Overall, the initialize function (1) sets up the necessary components for the inference runner, including the model, tokenizer, and associated operations. It also handles distributed computation and compilation of model functions for efficient execution during inference. Here’s a breakdown of its components:
- Initialization of Runner and Data:
- The function starts by extracting the
runnerattribute and initializing a dummy data dictionary (dummy_data) containing placeholders for inputs and targets (in essence, two arrays of zeros).
- The function starts by extracting the
- Initialization of Model and Tokenizer:
- The model is initialized using the
runner.initialize()method, passing the dummy data and configuration parameters. - The SentencePiece tokenizer is initialized using the provided
tokenizer_path.
- The model is initialized using the
- Extraction of Model Parameters:
- Parameters such as
max_len(maximum sequence length) andvocab_sizeare extracted from the model for further use.
- Parameters such as
- Padding Function:
- Defines a
pad_to_max_lenfunction, which pads sequences to the maximum length expected by the model.
- Defines a
- Functions for Model Operations:
- Defines several functions (
hk_forward,hk_sample_step,hk_new_memory,hk_prefill_memory) to perform various model operations such as forward pass, sampling, memory initialization, and prefilling.
- Defines several functions (
- Sharding and Compilation:
- Prepares model sharding for distributed computation using
jax.tree_util.tree_map_with_path. - Compiles the functions for sampling and prefilling memory using
hk.without_apply_rngandpjit.pjit.
- Prepares model sharding for distributed computation using
- Final Setup:
- Sets up RNG (random number generator) key for model initialization.
- Initializes
dummy_tokensfor evaluating shapes. - Computes shapes using
jax.eval_shape.
- Parameter Sharding:
- Computes parameter sharding using
jax.tree_util.tree_map_with_pathandapply_rulesfrom the model’s partition rules.
- Computes parameter sharding using
- Compilation of Sampling and Prefill Memory Functions:
- Uses
pjit.pjitto compile the sampling and prefill memory functions with appropriate input and output sharding configurations.
- Uses
Inference Runner running
After initialization, the inference can begin. The run() method efficiently generates text by sampling from the language model in response to prompts and yields the generated text to the caller when requested. It handles multiple requests concurrently and efficiently utilizes resources through asynchronous data copying. Let’s break down its functionality:
- Initialization: The method initializes various parameters and settings required for generating text, such as random number generators (
rngs), memory buffers (memory), and sample settings. - Preparation: It prepares a prompt array and settings for sampling. The prompt is padded to a suitable length, and settings like temperature and nucleus probability are set.
- Compiling: The method compiles the model for sampling. This might involve precompiling the model for different prompt sizes and compiling the model for actual sampling.
- Sampling Loop: The method enters a loop where it continually samples tokens from the model in response to prompts. It yields generated text when requested by the caller.
- Asynchronous Copying: During the sampling loop, it asynchronously copies data between devices and hosts to avoid blocking.
- Handling Requests: It processes requests for text generation, updating the state accordingly.
- Continuation: It continues the sampling loop until interrupted or until all requests are fulfilled.
Model
The model.py file contains all the architectural features and various support functions. It is about 1400 lines of code, we’ll try to summarize. We reiterate that the code uses JAX and Haiku, a library that simplifies the process of building and training neural networks in JAX, providing a high-level interface while maintaining the performance benefits of JAX’s low-level primitives. It’s commonly used in machine learning research and development where JAX is the preferred framework for its flexibility and performance.
The first lines are about 8bit quantizing weights, registering them as a Pytree nodes (enabling efficient processing and manipulation using JAX’s powerful array-based operations and transformations), sharding constraints based on the presence of a distributed computing environment, rules defining a specific pattern to enable efficient distribution and parallelization of computations in a transformer model across multiple devices or processors.
Then come all the classes strictly related to the definition of MoE + Transformer architecture: Router, MoE layer, MultiHead Attention, Decoder, Transformer, Attention Mask, RMS Norm, Rotary Embedding.
Finally, language model and its configuration are defined. These classes integrate embedding, positional encoding, transformer layers, and decoding logic to generate logits for next-token prediction. They ensures proper handling of padding, masking, and distributed computation if configured.
Conclusions
We briefly discussed the Grok-1 code, which is easy to understand and well written. The model should be tested on huge machines but it is probably still immature for a definitive and high-performance version. At the time of writing, a 1.5 version of Grok already appears to be on the way – again, not state of the art… size isn’t everything in artificial intelligence.
Useful links
xAI – Open Release of Grok-1 (link)
Open Release of Grok-1 – GitHub repository (link)
xAI – Announcing Grok (link)
Hugging Face – Mixture of Experts explained (link)
xAI – Announcing Grok-1.5 (link)
Also available on Substack





 and a passage
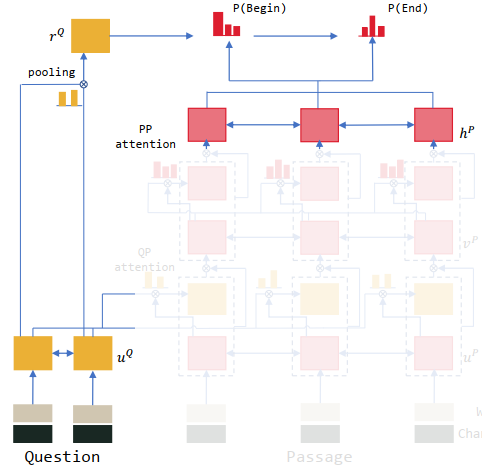
and a passage  . We begin with preprocessing and text encoding. The preprocessing is done in a separate process and is not part of the neural network. First we preprocess by splitting data into parts, and then we convert all the words to corresponding vectors, world-level embeddings
. We begin with preprocessing and text encoding. The preprocessing is done in a separate process and is not part of the neural network. First we preprocess by splitting data into parts, and then we convert all the words to corresponding vectors, world-level embeddings  and
and  . Each word is represented by a concatenation of two vectors: its
. Each word is represented by a concatenation of two vectors: its  and
and  . The latter embeddings are generated by taking the final hidden states of a BiRNN applied to embeddings of characters in the token.
. The latter embeddings are generated by taking the final hidden states of a BiRNN applied to embeddings of characters in the token.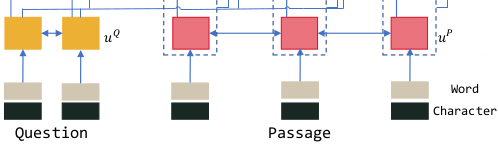
 and
and  of all the words in the question and passage:
of all the words in the question and passage:![u^Q = \mathrm{BiRNN}Q(u_{t{-}1}^Q, [e_t^Q, c_t^Q])](https://s0.wp.com/latex.php?latex=u%5EQ+%3D+%5Cmathrm%7BBiRNN%7DQ%28u_%7Bt%7B-%7D1%7D%5EQ%2C+%5Be_t%5EQ%2C+c_t%5EQ%5D%29+&bg=ffffff&fg=000000&s=1&c=20201002)
![u^P = \mathrm{BiRNN}P(u_{t-1}^P, [e_t^P, c_t^P]).](https://s0.wp.com/latex.php?latex=u%5EP+%3D+%5Cmathrm%7BBiRNN%7DP%28u_%7Bt-1%7D%5EP%2C+%5Be_t%5EP%2C+c_t%5EP%5D%29.++&bg=ffffff&fg=000000&s=1&c=20201002)
![[a, b]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%5D+&bg=ffffff&fg=000000&s=1&c=20201002) represents the concatenation of vectors
represents the concatenation of vectors  and
and  . As implementation, it is fine to use GRU networks as BiRNN cells and setting word vector to all zeros when the word is missing from GloVe.
. As implementation, it is fine to use GRU networks as BiRNN cells and setting word vector to all zeros when the word is missing from GloVe. and the passage representation
and the passage representation  , the aim is to generate question-aware representation of the passage
, the aim is to generate question-aware representation of the passage  feeding the previous state
feeding the previous state  and an attention-pooling vector
and an attention-pooling vector  into the RNN:
into the RNN: .
.

 .
. by vectors
by vectors  , take hyperbolic tangent activation tanh, multiply by a weight vector
, take hyperbolic tangent activation tanh, multiply by a weight vector  (a learned vector), then take softmax to express the “importance” of each word in the question (this is the similarity in additive attention). So we compute the product of
(a learned vector), then take softmax to express the “importance” of each word in the question (this is the similarity in additive attention). So we compute the product of  (question representation) by the attention vector to obtain a weighted — by attention scores –average of question word vectors.
(question representation) by the attention vector to obtain a weighted — by attention scores –average of question word vectors.  is the representation of the part of the question relevant to the current word from the passage.
is the representation of the part of the question relevant to the current word from the passage.![[u_{t}^P, c_{t}]](https://s0.wp.com/latex.php?latex=%5Bu_%7Bt%7D%5EP%2C+c_%7Bt%7D%5D++&bg=ffffff&fg=000000&s=1&c=20201002) instead of using just
instead of using just  (so we are considering information from the “original” input
(so we are considering information from the “original” input  ):
):![v_t^P = \mathrm{RNN}(v_{t-1}^P, [u_t^P,c_t])](https://s0.wp.com/latex.php?latex=v_t%5EP+%3D+%5Cmathrm%7BRNN%7D%28v_%7Bt-1%7D%5EP%2C+%5Bu_t%5EP%2Cc_t%5D%29++&bg=ffffff&fg=000000&s=1&c=20201002) .
.![[u_{t}^P,c_{t}]](https://s0.wp.com/latex.php?latex=%5Bu_%7Bt%7D%5EP%2Cc_%7Bt%7D%5D+++&bg=ffffff&fg=000000&s=1&c=20201002) . The gate is obtained taking the product of some new weight matrix
. The gate is obtained taking the product of some new weight matrix  and the concatenated vector
and the concatenated vector ![[u_{t}^P,c_t]](https://s0.wp.com/latex.php?latex=%5Bu_%7Bt%7D%5EP%2Cc_t%5D+++&bg=ffffff&fg=000000&s=1&c=20201002) , then using a sigmoid activation function.
, then using a sigmoid activation function.![g_t = \mathrm{sigmoid}(W_g, [u_{t}^P,c_t])](https://s0.wp.com/latex.php?latex=g_t+%3D+%5Cmathrm%7Bsigmoid%7D%28W_g%2C+%5Bu_%7Bt%7D%5EP%2Cc_t%5D%29+&bg=ffffff&fg=000000&s=1&c=20201002) .
. is a vector of non-negative entries, which is then (element-wise) multiplied by the original concatenated vector
is a vector of non-negative entries, which is then (element-wise) multiplied by the original concatenated vector ![[u_t^P,c_t]](https://s0.wp.com/latex.php?latex=%5Bu_t%5EP%2Cc_t%5D+&bg=ffffff&fg=000000&s=1&c=20201002)
![[u_{t}^P, c_t]^\ast = g_t \odot[u_t^P,c_t] \,.](https://s0.wp.com/latex.php?latex=%5Bu_%7Bt%7D%5EP%2C+c_t%5D%5E%5Cast+%3D+g_t+%5Codot%5Bu_t%5EP%2Cc_t%5D+%5C%2C.++&bg=ffffff&fg=000000&s=1&c=20201002)

 has a very limited knowledge of context. Here the vector
has a very limited knowledge of context. Here the vector  is passed as the input for the self-matching attention module. So, the question-aware passage representation is directly matched against itself. It dynamically collects evidence from the whole passage for words in passage and encodes the evidence relevant to the current passage word and its matching question information into the passage representation
is passed as the input for the self-matching attention module. So, the question-aware passage representation is directly matched against itself. It dynamically collects evidence from the whole passage for words in passage and encodes the evidence relevant to the current passage word and its matching question information into the passage representation  .
.
 is
is![h_t^P = \mathrm{BiRNN}(h_{t-1}^P, [v_t^P, c_t ] )](https://s0.wp.com/latex.php?latex=h_t%5EP+%3D+%5Cmathrm%7BBiRNN%7D%28h_%7Bt-1%7D%5EP%2C+%5Bv_t%5EP%2C+c_t+%5D+%29++&bg=ffffff&fg=000000&s=1&c=20201002)
 at time
at time  ):
):


 is a weight vector, the weights matrices
is a weight vector, the weights matrices  and
and  are different. An additional gate as in gated attention-based recurrent networks is applied to
are different. An additional gate as in gated attention-based recurrent networks is applied to ![[v_{t}^P, c_t]](https://s0.wp.com/latex.php?latex=%5Bv_%7Bt%7D%5EP%2C+c_t%5D++&bg=ffffff&fg=000000&s=1&c=20201002) to adaptively control the RNN input.
to adaptively control the RNN input.
 , the attention mechanism is used as a pointer to select the start position
, the attention mechanism is used as a pointer to select the start position  and the end position
and the end position  from the passage:
from the passage:


 represents the last hidden state of the answer RNN (pointer network). The initital hidden state is the output of the question pooling. The
represents the last hidden state of the answer RNN (pointer network). The initital hidden state is the output of the question pooling. The  at time
at time  vector is the predicted starting point. The input of the answer RNN is the attention-pooling vector based on current predicted probability
vector is the predicted starting point. The input of the answer RNN is the attention-pooling vector based on current predicted probability  :
:

 . The vector
. The vector  is an attention–pooling vector of the question based on the parameter
is an attention–pooling vector of the question based on the parameter  (as usual, the equations are those of an attention model):
(as usual, the equations are those of an attention model):